
5-10×
Faster than CPU-based in-browser inference
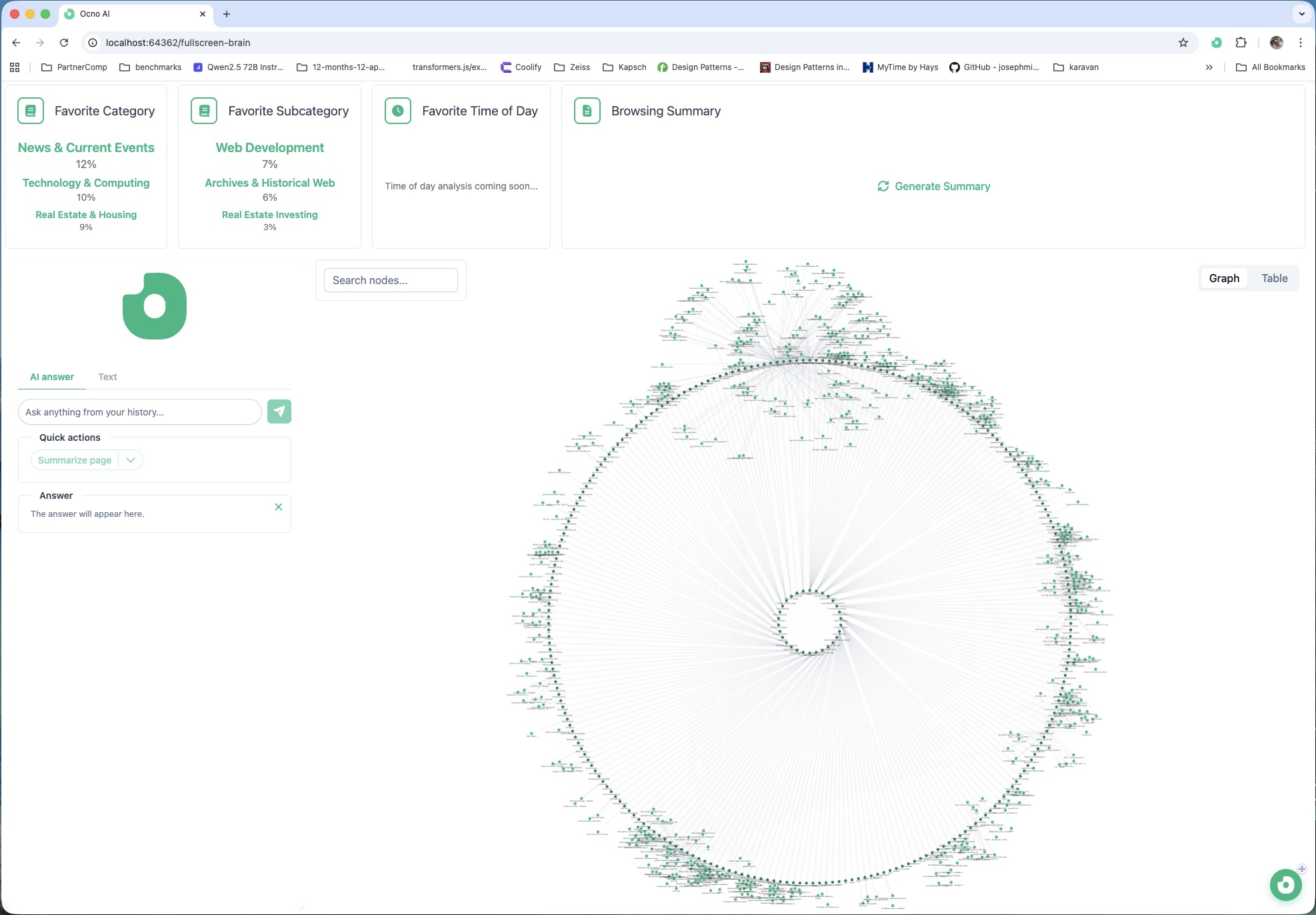
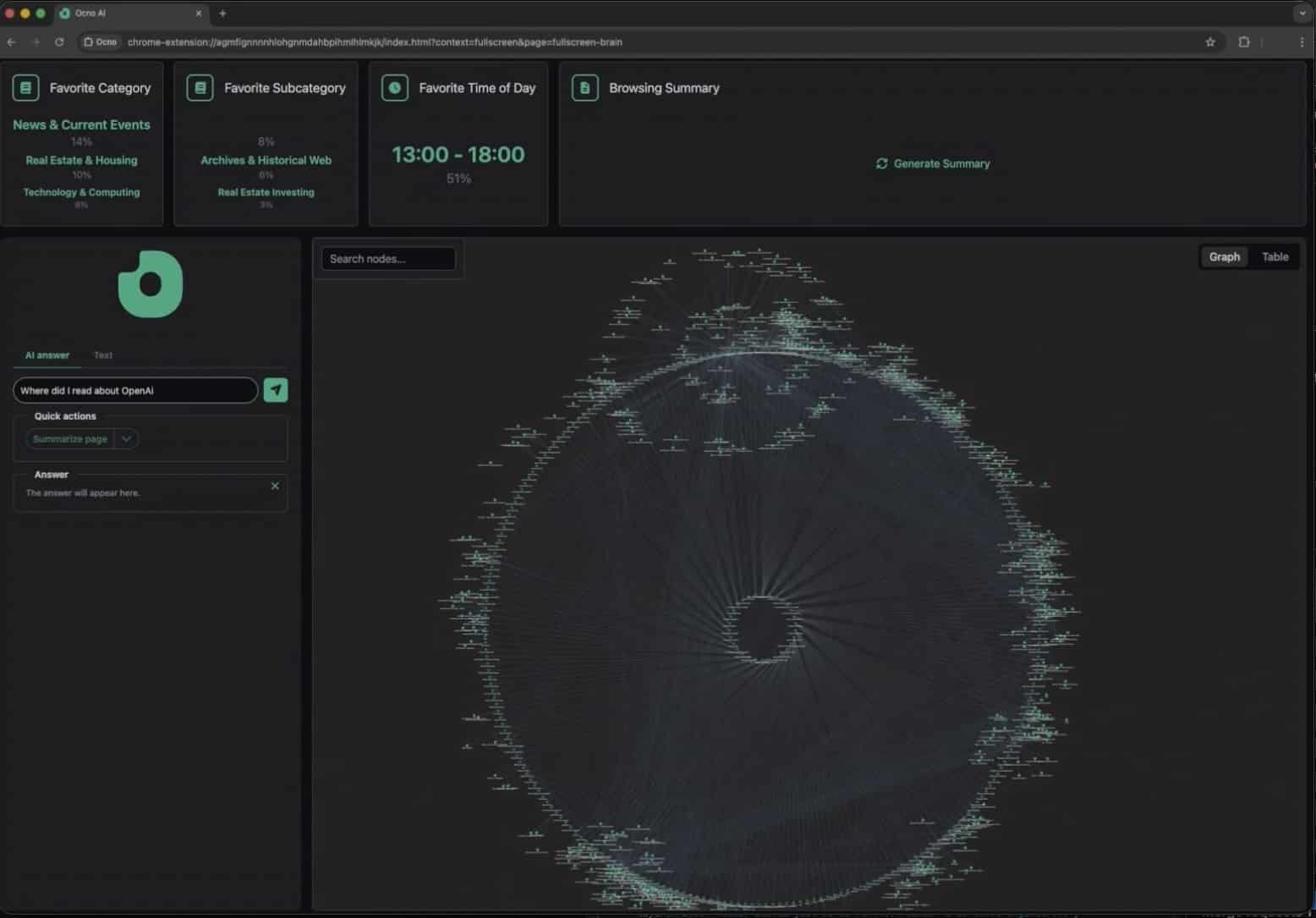
“Where did I read that?” recall
On-page explain/summary/translate without copy-paste
A visual Brain that reconnects ideas
Faster than CPU-based in-browser inference
Local execution - your data never leaves your machine
RAM needed for models comparable to GPT-4o quality
Ongoing subscription cost once you're running locally
Get occasional notes about private AI browsing, productivity workflows, and product updates.
FEATURES
Everything you need to turn passive browsing into active, connected knowledge.
Your browsing becomes a connected cognitive map. Pages, ideas, and topics form structured relationships you can explore visually.
Surfaces updates based on your real interests — not generic algorithms. Your curiosity becomes the signal.
Ask Ocno directly on any page. Explain concepts, summarize, clarify — without copying or switching tools.
Connects your current page with what you’ve read before. Relevant context resurfaces automatically.
Write key points. Let Ocno refine, expand, restructure — or translate instantly. Perfect for emails, reports, drafts.
Ask Ocno how to accomplish something on a page. Steps are highlighted directly in the interface. No friction.
ARCHITECTURE
No data leaves your device. Ever. Here's exactly what talks to what.

Each day, the OCNO server crawls public news sources and delivers the full article bundle to your device in bulk. Because everything arrives upfront, the server does not know what you actually read or like.
A local ranker compares that bundle against your own browsing context, memory, and reading profile - entirely on-device.
The server provides the inputs, but it does not see the local signals or ranking logic that shape your feed. The relevance layer lives on your side of the boundary.
VALUES
Every design decision in Ocno follows from these principles - nothing is compromised.
WHO IT'S FOR
Ocno is built for anyone who reads deeply, researches seriously, and can't afford to lose what they've already learned.

In the morning, Ocno surfaces relevant updates based on what you’ve been exploring — frameworks, libraries, tools, discussions — pulled from multiple trusted sources.
While building or debugging: “I’ve seen this before.” Ocno reconnects past solutions, research, and documentation.
While reading documentation or technical articles: Ask Ocno. Explain this. Ocno clarifies concepts directly on the page.
Thanks to its compiler-optimized engine and full GPU utilization, Ocno delivers up to 5–10× higher performance compared to traditional CPU-based in-browser model execution.
Smaller models like Qwen3 4B (GPU and 4GB RAM needed) can achieve quality comparable to large earlier models such as GPT-4o in many tasks proven by various benchmarks.
Advances in quantization and model compression drastically reduced memory requirements, making powerful models practical on everyday devices. You can now run model comparable to GPT-4o on just 3–4 GB of RAM — enabling capabilities once limited to large cloud systems.
Minimum: 8GB
Good: 16GB
Best: 32GB+
Minimum: M1
Good: M1 Pro
Best: M3 Max+
Recommended Baseline
MAKER
I replaced my social life with shipping.
